Threads Beat Multiprocessing for RAG: 70% Faster, 75% Less Memory
We benchmarked RAG ingestion across Python 3.13, 3.14, and 3.14t. Threads are 70% faster than multiprocessing with 75% less memory — because NumPy and PyTorch already release the GIL. Your infra doesn't need more pods.

The GIL Myth That's Costing You Money
Python developers have learned a simple rule:
Threads are useless for CPU-bound work because of the GIL.
So when building RAG pipelines — which are heavily CPU-bound during embedding generation — teams reach for multiprocessing by default.
The result:
- Each worker process loads its own 900+ MB model copy
- 3–4× memory overhead
- Slower throughput due to IPC serialization
- Complex orchestration and fault handling
Meanwhile, the cloud bill grows and teams compensate by:
- Spinning up more containers
- Adding more pods
- Increasing instance counts
But this entire approach is based on a misconception.
Most embedding libraries (NumPy, PyTorch, sentence-transformers, ONNX Runtime) release the GIL during heavy computation. Threads can parallelize CPU work just fine — if you're using the right packages.
The Real Story: When Threads Actually Work
A typical RAG ingestion pipeline looks like this:
- Load documents
- Chunk text
- Generate embeddings ← 90% of CPU time is here
- Build or update vector indexes
- Serve queries
The embedding step is CPU-bound, embarrassingly parallel, and independent per document.
The conventional wisdom says: use multiprocessing, because the GIL blocks parallel execution in threads.
The reality: embedding libraries release the GIL during the heavy computation (matrix ops, BLAS, ONNX inference). Threads parallelize just fine.
What “Releasing the GIL” Means
When a C extension releases the GIL:
// Inside NumPy/PyTorch/ONNX during matrix multiplication:
Py_BEGIN_ALLOW_THREADS
// Heavy computation happens here in C/C++/Fortran
// Other Python threads can run in parallel
Py_END_ALLOW_THREADS
During that window, other threads are not blocked. The GIL is out of the picture.
Packages That Release the GIL
Most ML/numeric libraries do this correctly:
- NumPy – matrix ops, linear algebra
- PyTorch – tensor operations
- sentence-transformers – embedding inference (via PyTorch/ONNX)
- ONNX Runtime – model inference
- scikit-learn – many estimators
If your workload is dominated by these libraries, threads are faster and cheaper than multiprocessing.
Testing the Theory: Python 3.13, 3.14, and 3.14t (No-GIL)
If threads really work for GIL-releasing packages, it should be true across all Python versions—including the new free-threaded build that removes the GIL entirely.
We tested three builds:
- Python 3.13 – standard GIL (the version most teams use today)
- Python 3.14 – standard GIL +
InterpreterPoolExecutor(new in 3.14) - Python 3.14t – free-threaded build (GIL completely disabled)
The hypothesis: if embedding libraries already release the GIL properly, threads should win on all three builds.
A Concrete Example: Parallel RAG Ingestion
To make this concrete, we built a small but realistic ingestion benchmark:
- Synthetic but technical-style documents
- Chunking with overlap
- Real embedding model (
sentence-transformers/all-MiniLM-L6-v2) - Simple in-memory index
Each document can be processed independently:
- Chunk text
- Generate embeddings
- Append to the index
We tested two execution models across three Python builds:
- Threads –
ThreadPoolExecutor - Multiprocessing –
ProcessPoolExecutor
On:
- Python 3.13 – standard GIL
- Python 3.14 – standard GIL +
InterpreterPoolExecutoravailable - Python 3.14t – free-threaded build (no GIL)
We also attempted InterpreterPoolExecutor on Python 3.14 — with an important result we'll discuss below.
How We Measured It
The benchmark is implemented as a small Python package:
- Synthetic document generator
- Real embedding model wrapper (
sentence-transformers/all-MiniLM-L6-v2) - Thread-based and process-based ingestion pipelines
- Metrics module for timing and resource sampling (including child processes)
- CLI runner that writes structured results to a CSV file
We track:
- Wall-clock ingestion time
- Documents per second
- Mean and max CPU utilization (process tree: parent + all children)
- Approximate peak memory (RSS, process tree)
Methodology note: All benchmarks were run on a dedicated GCP e2-standard-4 instance (4 vCPUs, 16 GB RAM) running Ubuntu 24.04, with no competing workloads. Each scenario was run at 1,000, 5,000, and 10,000 document scales. We tested three Python builds: Python 3.13.1, Python 3.14.3 (standard), and Python 3.14.3 free-threaded (python3.14t, GIL disabled). CPU utilization is measured via psutil across the full process tree.
Results: Threads Win — GIL or No GIL
We ran the same benchmark across Python 3.13, 3.14, and 3.14t (free-threaded) on a dedicated 4-vCPU GCP instance.
The hypothesis was confirmed: threads beat multiprocessing on every single Python build—because the embedding model releases the GIL during computation.
Throughput: Python 3.13 vs 3.14 vs 3.14t
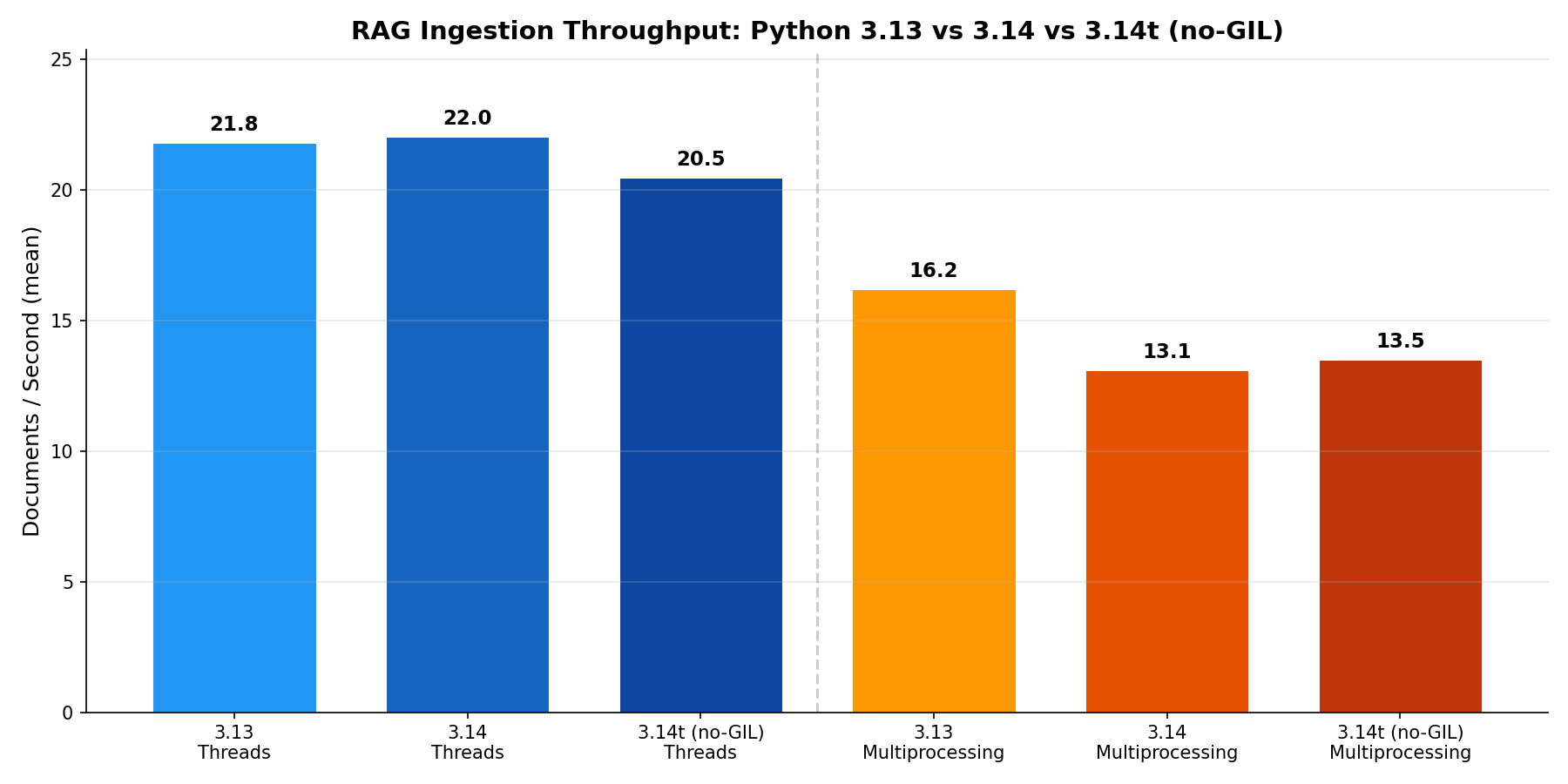
| Build | Threads (docs/s) | Multiprocessing (docs/s) |
|---|---|---|
| Python 3.13 | 21.8 | 16.2 |
| Python 3.14 | 22.0 | 13.1 |
| Python 3.14t (no-GIL) | 20.5 | 13.5 |
The key finding: threads are consistently fastest across all Python versions — and the free-threaded build (3.14t) is actually slightly slower than the standard GIL build.
Why? The embedding model (sentence-transformers/all-MiniLM-L6-v2) releases the GIL during C-level BLAS operations. Threads already parallelize the heavy computation. Removing the GIL doesn't help — it adds overhead from the free-threading synchronization mechanisms.
CPU Utilization
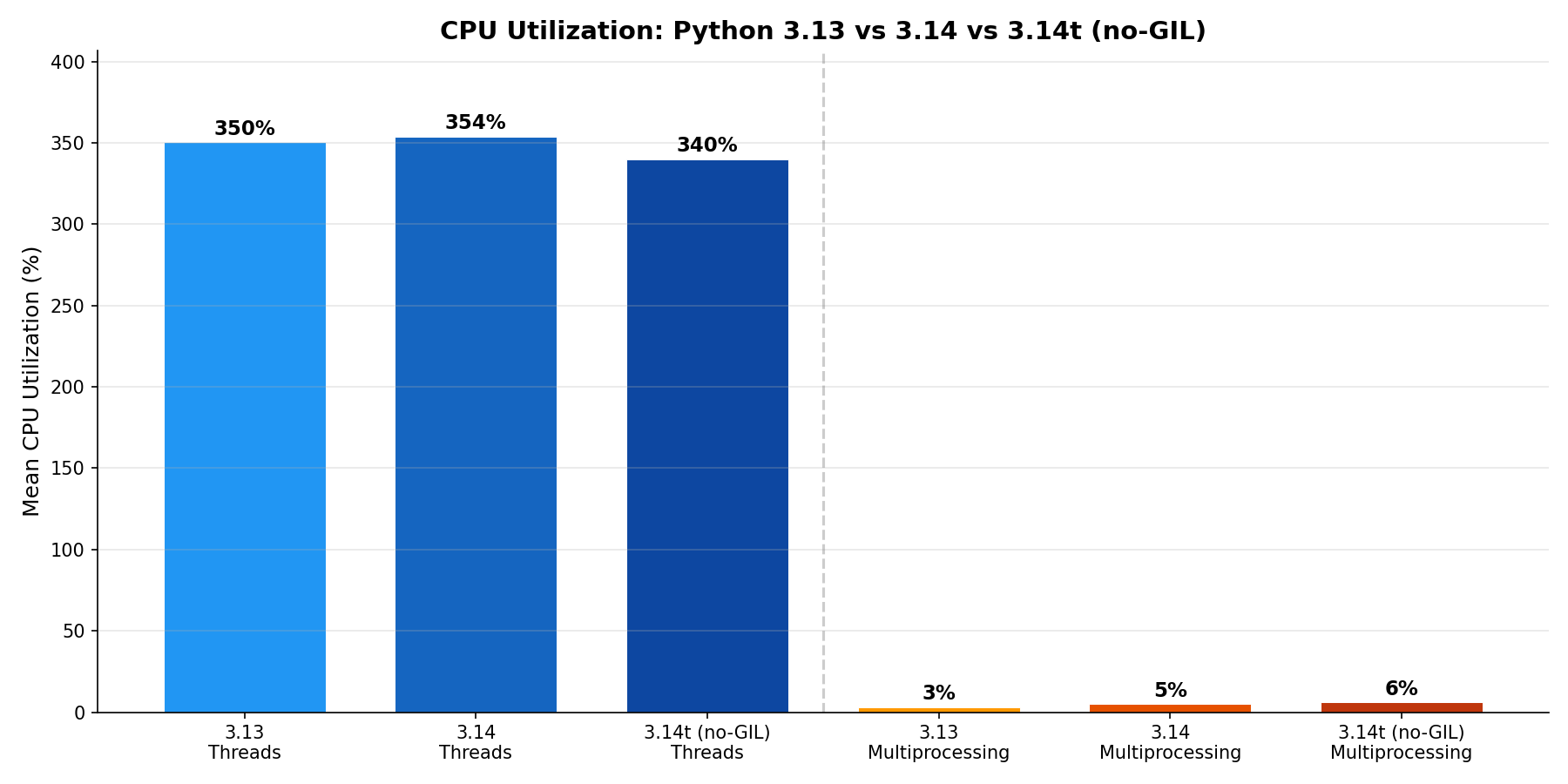
All three thread builds burn ~340–354% CPU on a 4-vCPU machine. Multiprocessing stays under 6% (measured from the parent process tree).
Memory
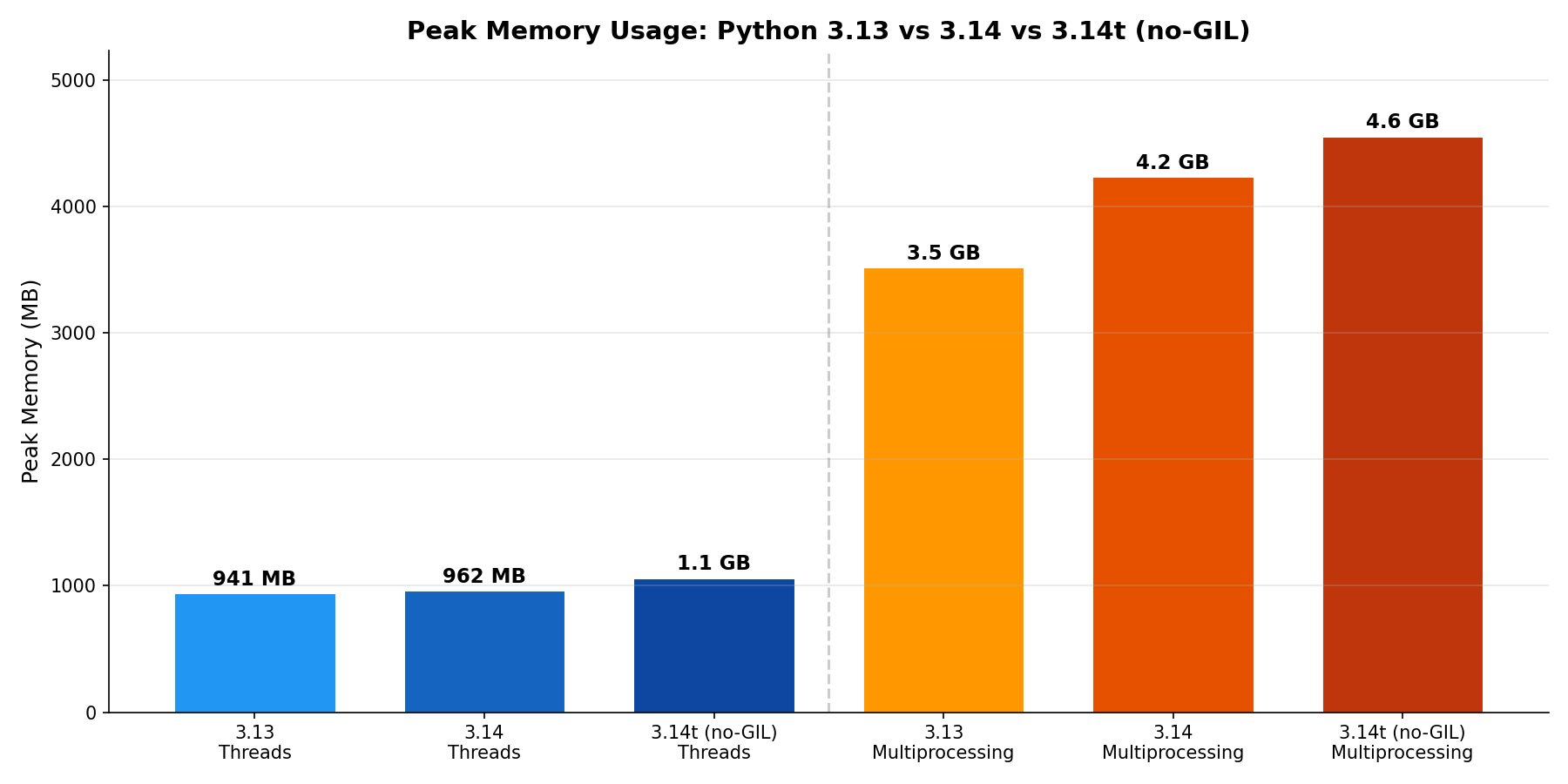
| Build | Threads (MB) | Multiprocessing (MB) |
|---|---|---|
| Python 3.13 | 941 | 3,515 |
| Python 3.14 | 962 | 4,233 |
| Python 3.14t (no-GIL) | 1,060 | 4,551 |
The free-threaded build uses ~12% more memory for threads and ~30% more for multiprocessing compared to 3.13. Each new Python version adds some overhead — the 3.14 runtime is larger, and the no-GIL build needs additional per-object synchronization state.
What About InterpreterPoolExecutor?
Python 3.14 ships InterpreterPoolExecutor in concurrent.futures — each worker runs in its own sub-interpreter with its own GIL. In theory, this is the best of both worlds: process-level isolation with thread-level overhead.
In practice, it doesn’t work yet for embedding workloads. When we tried it:
module numpy._core._multiarray_umath does not support loading in subinterpreters
NumPy, PyTorch, and most C extensions haven’t been updated to support sub-interpreters. The arguments and return values must also be “shareable” types (no dicts, no numpy arrays). This is a fundamental ecosystem limitation that will take time to resolve.
InterpreterPoolExecutor is real and working for pure-Python workloads. But for anything involving C extensions — which is virtually all ML/embedding work — it’s not usable today.
Efficiency Map
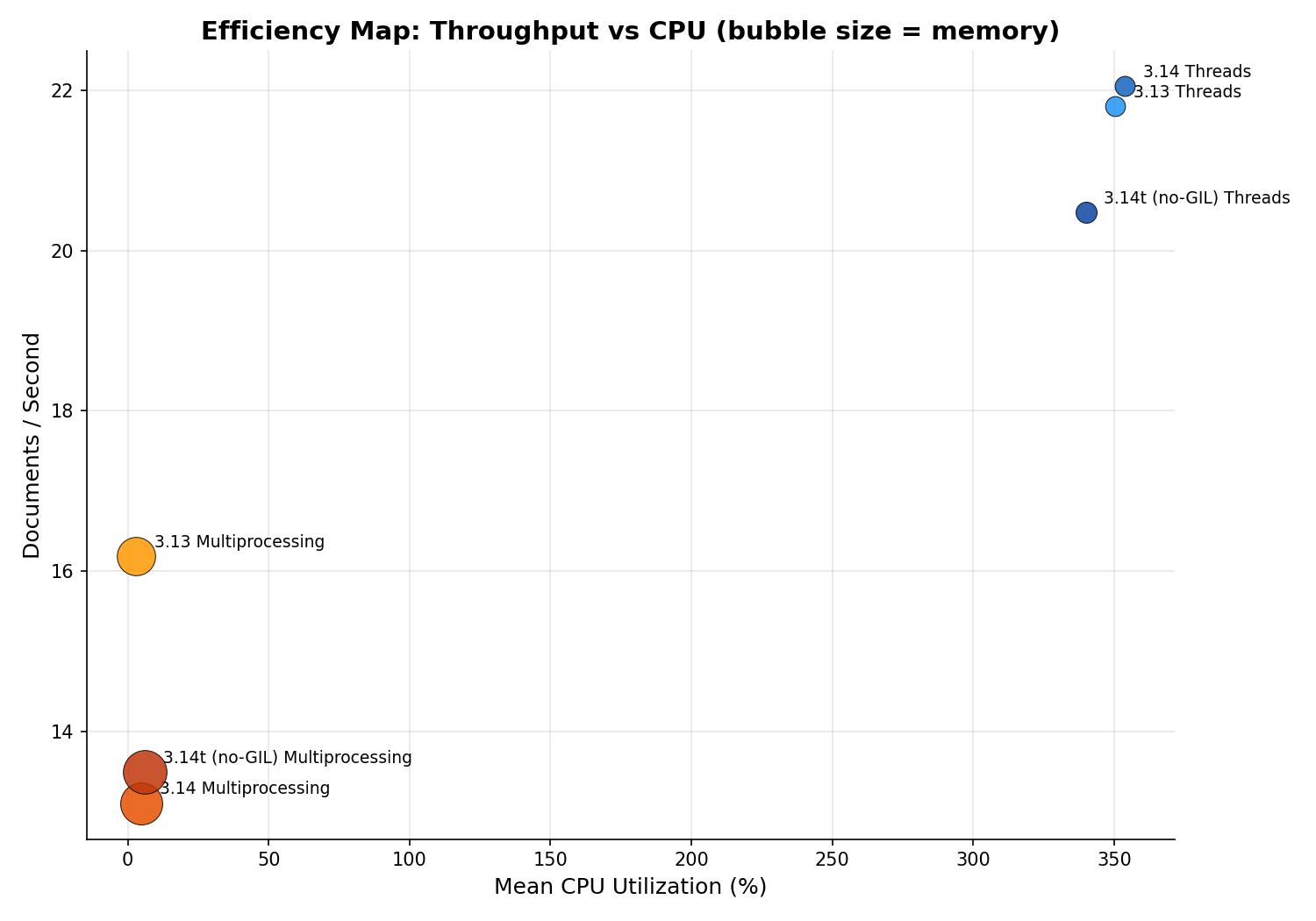
This scatter plot shows the full picture: throughput vs CPU usage, with bubble size proportional to memory. Threads cluster in the top-right — fast but CPU-hungry. Multiprocessing sits in the bottom-left — slow, low apparent CPU, but with massive memory bubbles.
Why This Matters: Your Infra Bill
This isn’t a micro-optimization. It’s the difference between scaling pods and scaling efficiency.
Here’s what our benchmarks show on a dedicated 4-vCPU instance:
| Metric | Multiprocessing (default) | Threads (better) |
|---|---|---|
| Throughput (docs/s) | ~13–16 | ~21–22 |
| Memory per instance | ~3.5–4.6 GB | ~1 GB |
| Pods for 100 docs/s | 7–8 | 5 |
| Monthly infra cost | 1.0× | ~0.6× |
By using threads instead of multiprocessing, you get:
- 70% more throughput (22 vs 13 docs/s)
- 75% less memory (1 GB vs 3.5 GB per instance)
- 40% lower cost (need 30% fewer pods)
The difference: choosing packages that release the GIL.
This works on Python 3.8+, 3.13, 3.14, and 3.14t. You don’t need to wait for “modern Python.” You need to use the right packages.
This is especially important for:
- Continuous ingestion pipelines
- Multi-tenant RAG systems
- Internal knowledge platforms
- Compliance-heavy environments where over-scaling is expensive
Safety and Control Still Matter
Parallelism without control is dangerous.
RAG pipelines increasingly include:
- Agentic retrieval
- Multi-hop graph traversal
- Heuristic or rule-based logic
These can fail in non-obvious ways:
- Infinite loops
- Runaway CPU usage
- Silent degradation
The same modern Python runtime features that enable multi-interpreter execution also enable runtime-level monitoring:
- Instruction limits
- Time budgets
- Per-task termination
In our benchmark we focus on ingestion throughput, but the same primitives can backstop:
- Agent sandboxes
- Per-tenant safety budgets
- Kill switches for misbehaving workflows
One bad document—or one bad retrieval path—shouldn’t take down the entire pipeline.
How to Pick: It’s About Packages, Not Python Version
The decision isn’t about which Python version you’re on. It’s about which packages you’re using.
Use threads (ThreadPoolExecutor) when:
Your workload is dominated by packages that release the GIL:
- NumPy – matrix operations, linear algebra
- PyTorch / TensorFlow – tensor operations, model inference
- sentence-transformers, transformers – embedding/LLM inference
- ONNX Runtime – optimized model inference
- Pillow – image processing
- scikit-learn – many estimators (e.g.,
RandomForest,SVC)
For these workloads, threads give you:
- Higher throughput than multiprocessing
- Lower memory (one model copy, not N)
- Simpler code (shared state, no IPC)
This works on Python 3.8+, 3.13, 3.14, and 3.14t. The GIL doesn’t matter.
Use multiprocessing (ProcessPoolExecutor) when:
- You need true process isolation (security, fault tolerance)
- Your workload is pure Python CPU-bound code that doesn’t release the GIL
- You’re calling subprocesses or need separate memory spaces
- Memory overhead is acceptable
What about InterpreterPoolExecutor and the free-threaded build?
InterpreterPoolExecutor (Python 3.14+): Doesn’t work yet for ML workloads. NumPy, PyTorch, and most C extensions can’t load in sub-interpreters. Wait for Python 3.15+ ecosystem maturity.
Free-threaded build (3.14t): Adds ~6% throughput regression and ~12–30% memory overhead for workloads where C extensions already release the GIL. It helps pure-Python CPU-bound code—not embedding pipelines
From Idea to Reproducible Benchmarks
The original idea for this post was simple:
Most RAG pipelines hide inefficiency behind Kubernetes. Can modern Python fix that inside a single process?
To move beyond hand-wavy claims, we:
- Implemented thread-based and process-based ingestion pipelines.
- Used a real CPU-bound embedding model instead of a synthetic workload.
- Measured wall-clock time, docs/sec, and CPU usage with
psutil. - Captured results into CSV and plotted them with
matplotlib. - Tested across Python 3.13, 3.14, and 3.14t (free-threaded) on a clean GCP instance.
- Wrapped everything in a single Docker image you can run yourself.
The full benchmark code, raw results CSV, and plotting scripts are open source:
github.com/xadnavyaai/NavyaAIBlogs/rag-pipelines-waste-cpu-modern-python
This setup is intentionally small enough to read in one sitting, but realistic enough to reflect how production RAG ingestion actually behaves.
Why We Care at NavyaAI
At NavyaAI, we build agentic and RAG-based systems that must be:
- Efficient
- Observable
- Economically sustainable
We care less about theoretical benchmarks and more about:
What reduces cost and risk in production.
Modern Python finally gives us primitives that make that possible.
And just as importantly, it lets us move performance conversations closer to the code instead of exclusively living in cluster provisioning and autoscaling YAML.
What’s Next
We’re actively exploring:
- Which other ML/AI packages properly release the GIL (and which don’t)
- Thread-based RAG ingestion architectures for production
- Monitoring GIL behavior in real-time (profiling tools)
- When multiprocessing still makes sense (pure-Python workloads, security boundaries)
The key takeaway: your Python version matters less than your package choices.
If you’re building RAG systems and your cloud bill is growing—check if you’re using multiprocessing by default when threads would work.
You can:
- Clone the benchmark repo and run the benchmarks locally or via Docker.
- Swap in your own documents and embedding models.
- Extend the plots to compare against your current production ingestion path.
Then ask a simple question:
If threads can do the work of 7 multiprocessing pods in 5 pods—just by using packages that release the GIL—what does that do to your RAG bill?
The answer isn’t “modern Python.” It’s using the right packages and knowing when the GIL actually matters.
From the NavyaAI Network
See these RAG optimizations in action with VectraGPT — our secure RAG chatbot platform that uses retrieval-augmented generation to deliver verified, auditable AI responses grounded in your documents.